What is DevOps and how is it so much bigger than automating deployments?
You know that a term you coined has made it mainstream when people use it regularly in conversations and rarely understand what you meant.
— Martin Fowler (paraphrased from an in-person conversation)
Rouan summarises DevOps culture well in his post on Martin’s bliki. It is easy for developers to get disinterested with operational concerns. “It works on my machine” used to be a common phrase between developers in yesteryears. Some operations folks can also be less concerned by development challenges. Increased collaboration can help build a bridge in the gap between Developers and Operations team members and thus make your product better.
This increased collaboration has made observed requirements like system and resource utilisation monitoring, (centralised) logging, automated and repeatable deployments, no slow-flake servers etc. key parts of our products. Each of these improve the quality of life of your product either by directly benefiting the end user or making the system more maintainable for Developers and Operations users thus reducing the time to fix issues for end user issues. Developers and Operations folks are also first class users of your system. Their happiness (ease of debugging issues, deploying etc.) is a key part of your product’s success. It allows them to spend more time improving your product for paying end users.
What is MLOps?
MLOps is a culture that increases collaboration between folks building ML models (developers, data scientists etc.) and people who monitor these models and ensure everything is working as intended (operations). The observed requirements in your system will have some overlaps with what we have already talked about like system and resource monitoring, (centralised) logging, automated and repeatable deployments, automated creation of repeatable (non-snowflake) infrastructure etc. It will also include a few Data Platform specific observed requirements such as model and data versioning, data lineage, monitoring effectiveness of your model over an extended period of time, monitoring data drift etc.
Some tools/techniques to build a robust data platform
The need of every data platform is slightly different based on the challenges you are solving and the scale at which you operate. One of the platforms I’ve been working on produces 2TB of data every week. It didn’t take too much time for data storage costs to be the number 1 line item on our bill and we invested some time in optimising our storage and retention strategy. Other teammates have lowered data volumes and focus on reducing the cycle time for model creation. Your mileage may vary.
Based on our experience building data platforms over the past few years, here are a few tools we have used and things we have watched out for.
Data Storage
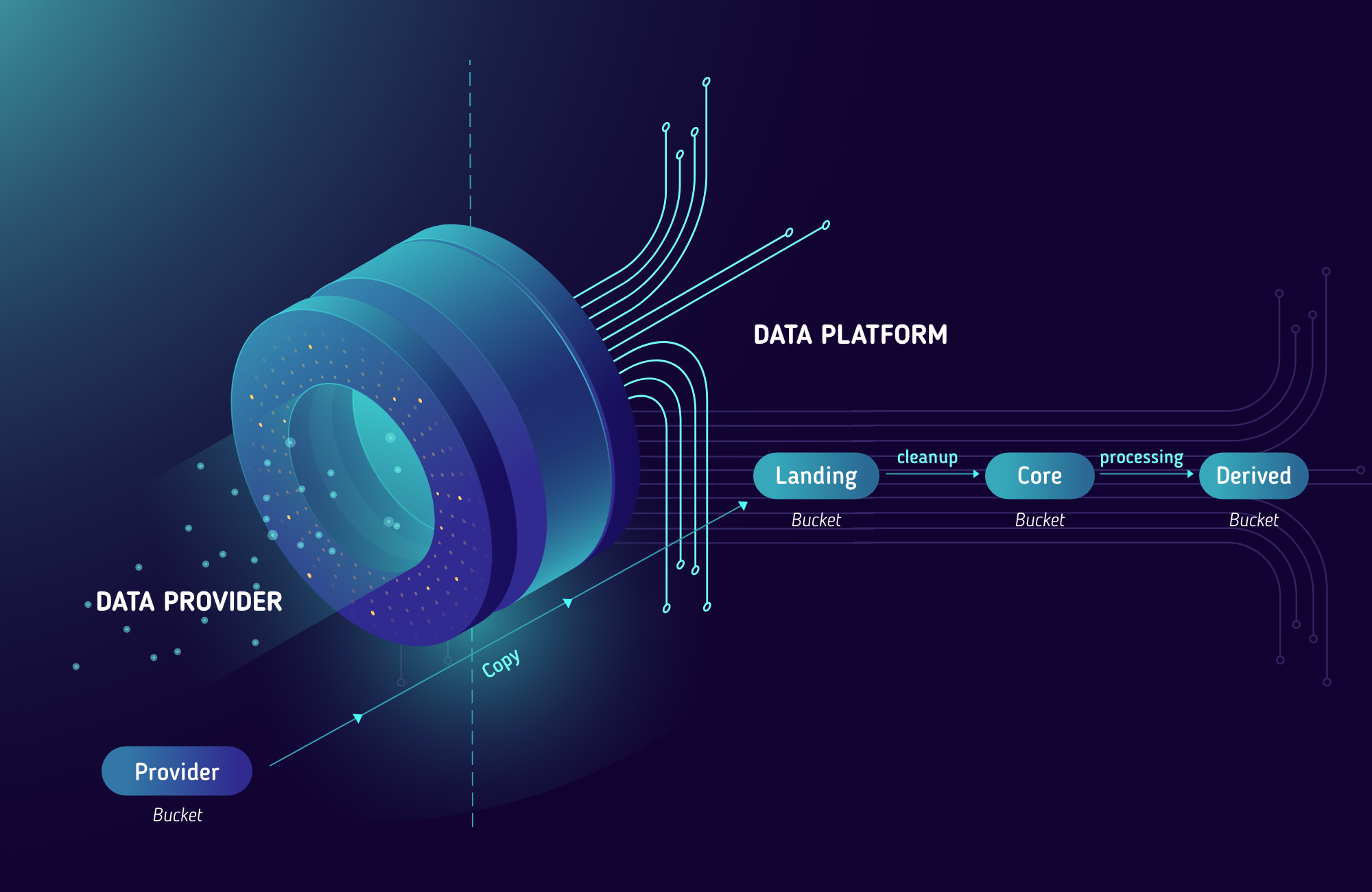
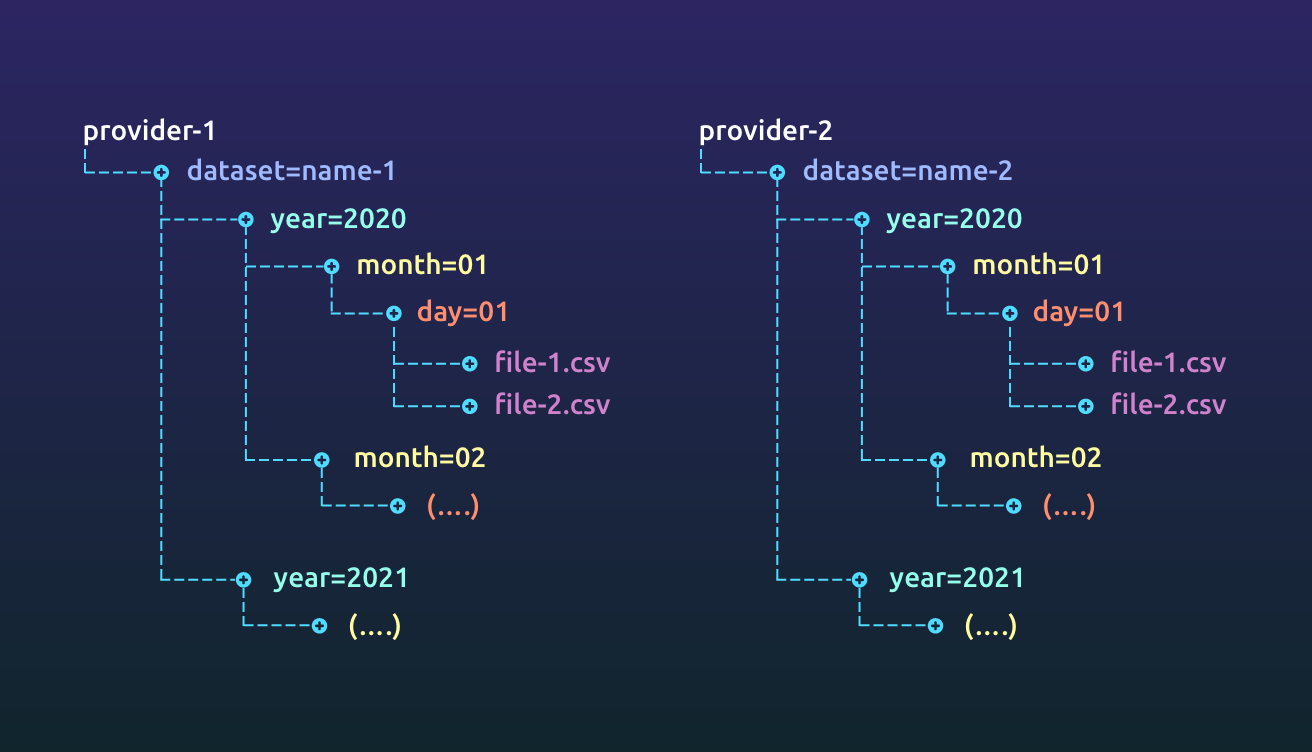
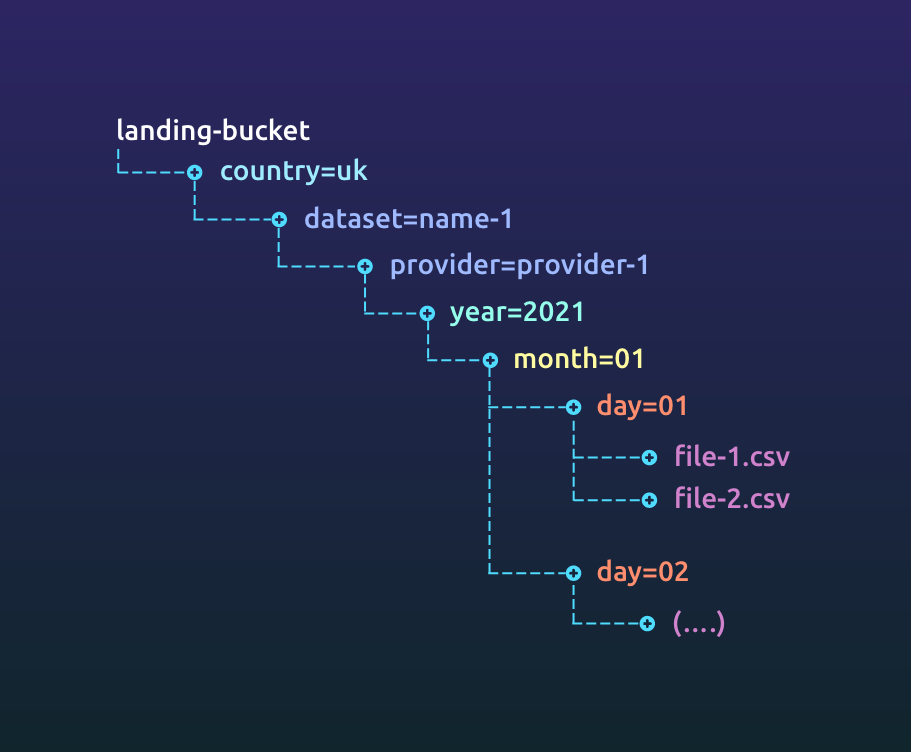
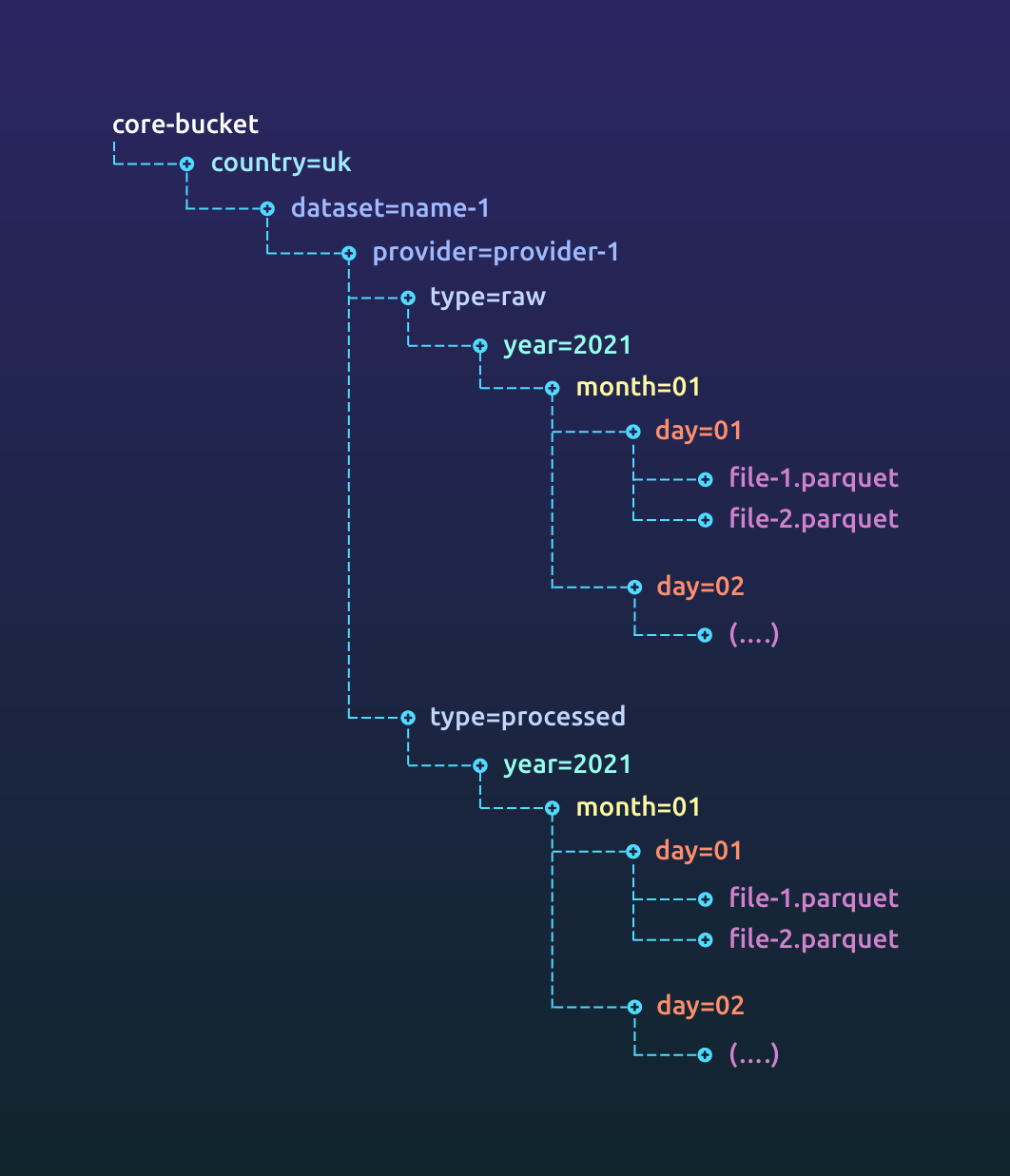
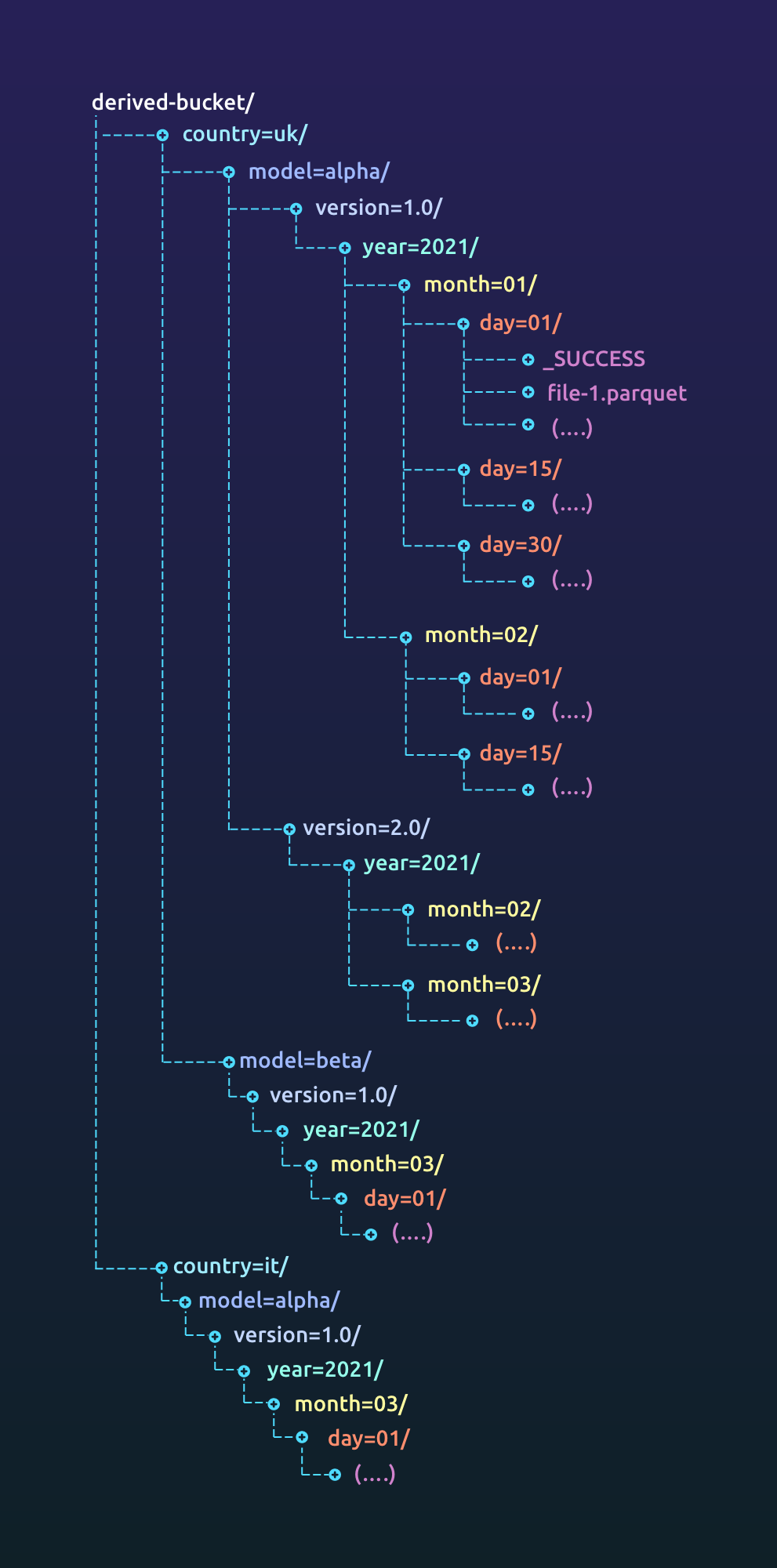
Choose a storage mechanism that provides cheap and reliable access to your data while meeting all legal requirements for your dataset. If you are in a heavily regulated environment (finance, medicine etc.), you might not be able to use the cloud for customer data. The techniques still remain similar. Partition your data based on access requirements and retention times. Archive data when you do not need it. Use features like push down predicates to efficiently read your data.
We recently wrote about data storage, versioning and partitioning which goes into great depth into this topic.
Job Scheduler/Workflow orchestrator
Your data pipelines will get complex over a period of time. Much like infrastructure as code, we would like our data pipelines in code. Apache Airflow is one of the tools that allows us to do this fairly easily. Sayan Biswas wrote about our airflow usage in 2019. Over the last few years, we have made dozens of improvements to the way we use Airflow. In a subsequent post in this series, we will talk through these improvements.
Monitoring and managing data processing costs
We spawn EMR clusters on demand and terminate them when jobs complete. A cluster runs only 1 spark job (and a few extra tasks for cleanups and reporting). If a job fails due to resource constraints, this helps isolate if another hungry job consumed too many resources before a scaling policy kicked in.
Each EMR cluster has an orchestrator node (AWS and Hadoop call them “master nodes”) and a group of core nodes (Hadoop calls them “worker nodes”). We request for on demand nodes for orchestrators and reserve the instances to reduce cost. We bid for spot instances for cores using a dynamic pricing strategy that is dependent on the current price. We have considered building a system that automatically switches instance types based on availability, price and stability in AWS but failures in spot bids are currently rare enough that it does not justify the cost of developing this feature.
We also monitor the resource utilisation of our spark jobs using Ganglia on AWS EMR. This tells us our CPU, memory, disk and network utilisation for our clusters. Since the information on Ganglia is lost when clusters are terminated, we run an EMR step to export a snapshot of Ganglia before the cluster terminates. This in conjunction with persisted spark history server data on AWS allows us to tune underperforming spark jobs. In a subsequent post, we will go into details of how to monitor your jobs effectively and tune them.
Monitoring the status of data pipeline jobs
Airflow creates EMR clusters and monitors each of the jobs. If a job fails, Airflow notifies us on a specific slack channel with links to the Airflow logs and AWS cluster.
Complex spark applications produce hundreds of megabytes of logs. These logs are distributed across the cluster and will be lost when the cluster is shut down. AWS EMR has an option to automatically copy the logs to S3 with a 2 minute delay.
We have tried using CloudWatch to index and analyse our spark logs but it was far too expensive. We also tried using a self hosted ELK stack but the cost of scaling it up for the volume of logs sent was too high. Dumping it on S3 and analysing it offline gave us the best cost to performance ratio.
To help reduce the time to fix an issue, when an issue is detected, the EMR cluster analyses its logs from YARN and publishes an extract onto slack as an attachment. Any further detailed analysis can be done on the logs in S3.
Monitoring data quality and data drift
Every time we write code, we run tests to ensure the code is safe to be deployed. Why don’t we do the same thing with data every time we access it?
When you first look at the data and build the model, you ensure the quality of the data used for training the model meets acceptable standards for your solution. Data Quality is measured by looking at the qualitative and quantitative pieces of your dataset. Over a period of time, these qualitative and quantitative attributes might drift causing adverse effects on your model. Thus, it is important to monitor your data quality and data drift. Data drift might be large enough that your model does not produce the right results any more or might be small enough to introduce a bias in your results. Monitoring these characteristics is key to producing accurate insights for your business.
Tools like Great Expectations and Deequ will ensure that your data is sound structurally and volumetrically. Deequ also has operators to look at rate of change of data which is a better expectation than having static thresholds on large volumes of data.
For example, given an employee salary database where the salary is nullable, a check to ensure no more than 100 employees out of the 1000 you currently have data for have no reported salary is bound to fail when the data volume increases significantly. If this check was to ensure no more than 10% of employees have no reported salary will work as the data scales as long as it scales evenly. Moving to a check that looks at rate of change of ratio of users not reporting a salary will be more robust. If the number changes significantly (up or down), it might mean that it’s time to tune your model since the source data is drifting away from when it was trained.
There are more complex examples on how we watch for data drift that will have to wait for a dedicated post.
The MLOps mindset
When our end users feel pain, we add new features to make their experience better. The same should be true for developers/operations experience (DevEx/OpsEx).
When it takes us longer to debug a problem or understand why a model did what it did, we improve our tooling and observability into our system. When it ran slower or was more expensive, we improved our observability to investigate inefficiencies quicker.
This has allowed us to grow our data platform 10x in terms of features and data volumes while reducing the time taken to produce insights for our end users by 98.75%, the cost to do so by 35% and not to mention a significant improvement in developer and customer experience.
Thanks to Jayant, Priyank, Anay and Trishna for reviewing drafts and providing early feedback. As always, Niki’s artwork wizardry is key!
]]>